Proyecto ELT - Dashboard
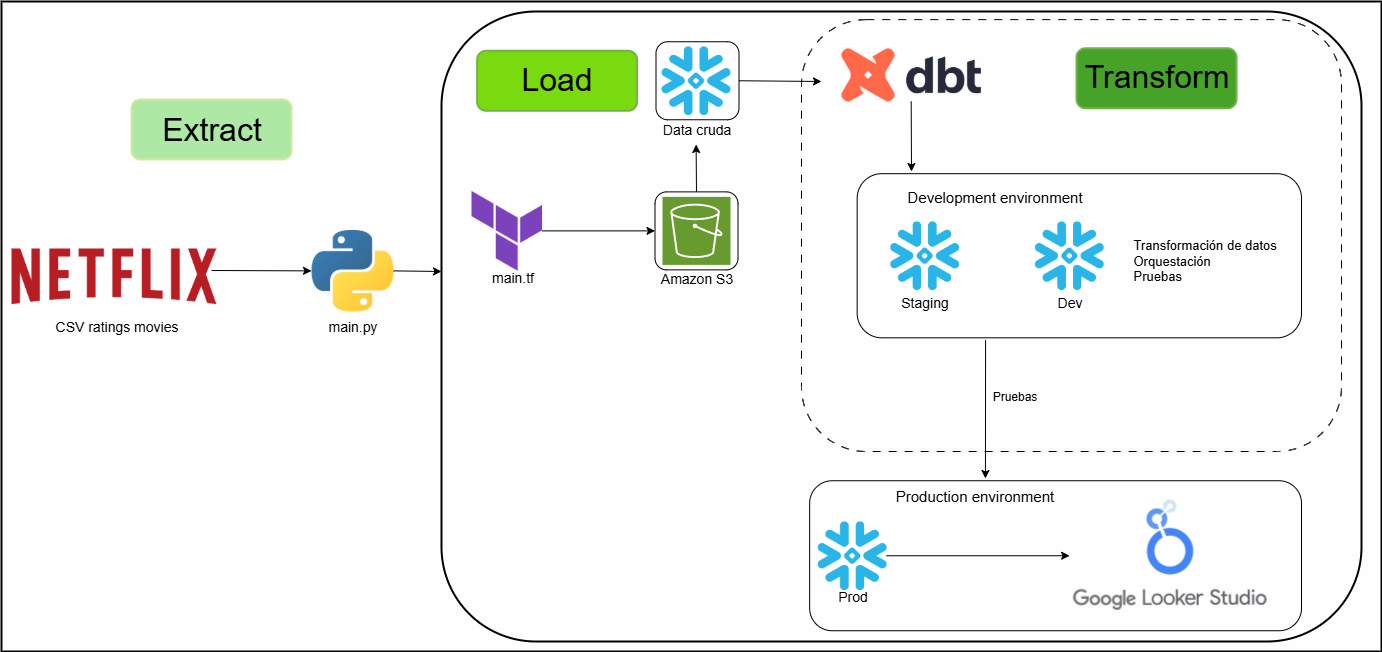
Workflow ELT
Diagrama completo del proceso ELT implementado en el proyecto.
Fuente de datos - Grouplens
Dataset original almacenado en Grouplens. Haz clic en la imagen para acceder al dataset.

Estructura de la base de datos relacional (warehouse)
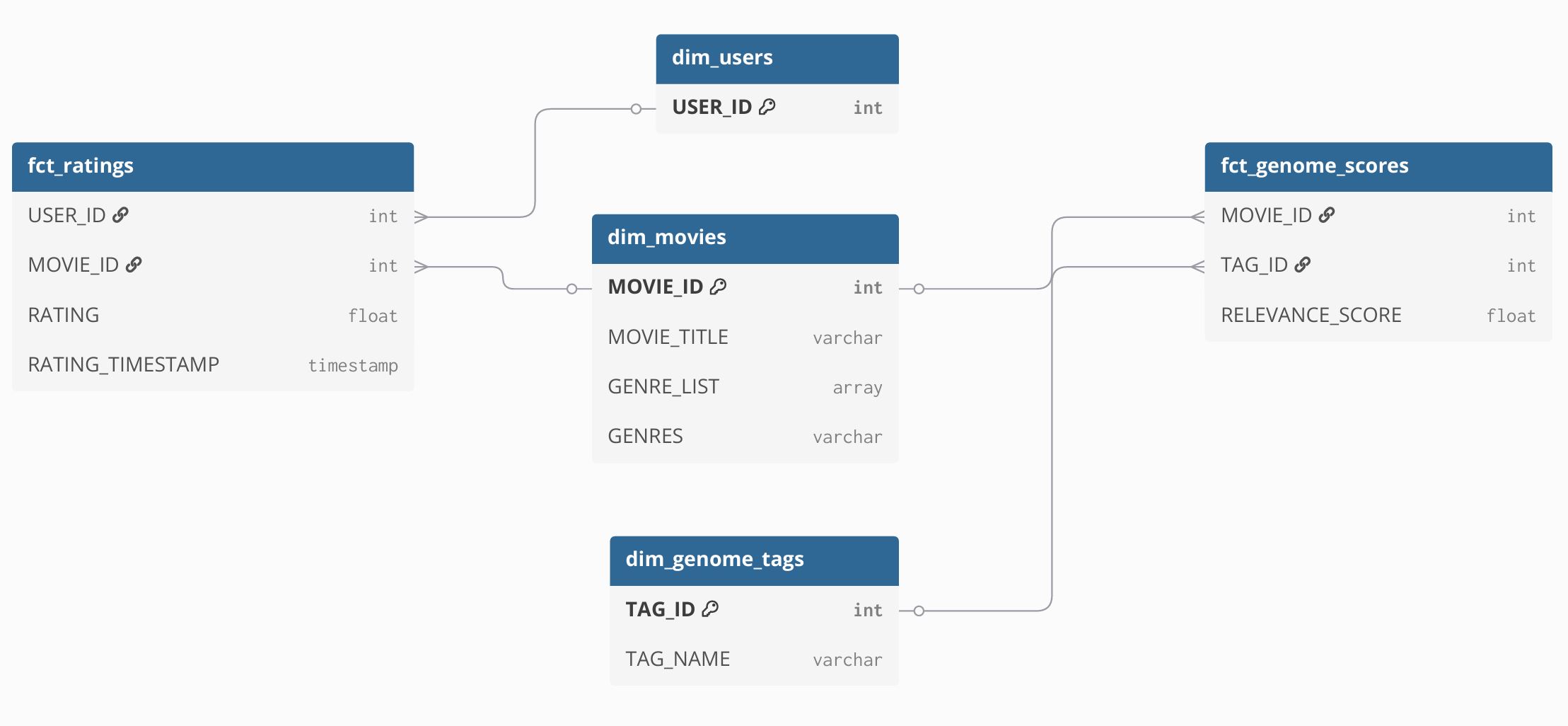
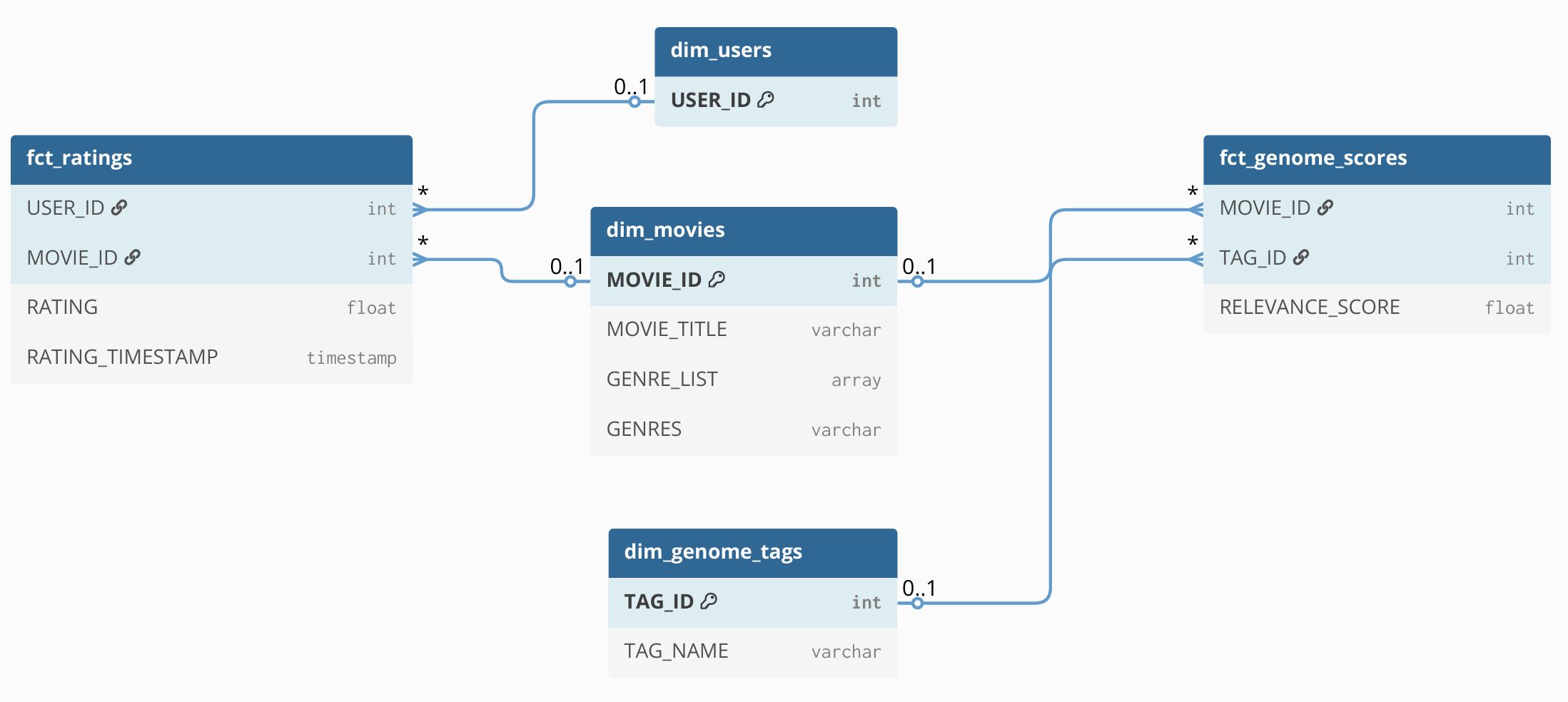
La base de datos se diseñó siguiendo el modelo en estrella (star schema), optimizado para consultas analíticas (OLAP) sobre datos de películas, usuarios y tags. Tablas de hechos: fct_ratings: Contiene las calificaciones de los usuarios para cada película, con timestamp asociado. fct_genome_scores: Registra la relevancia de cada tag para cada película. Tablas de dimensiones: dim_movies: Información descriptiva de películas y sus géneros. dim_genome_tags: Detalle de tags asociados a películas. dim_users: Identificadores y atributos de los usuarios.
Código del ELT
Implementación del proceso ELT dividido en módulos especializados:

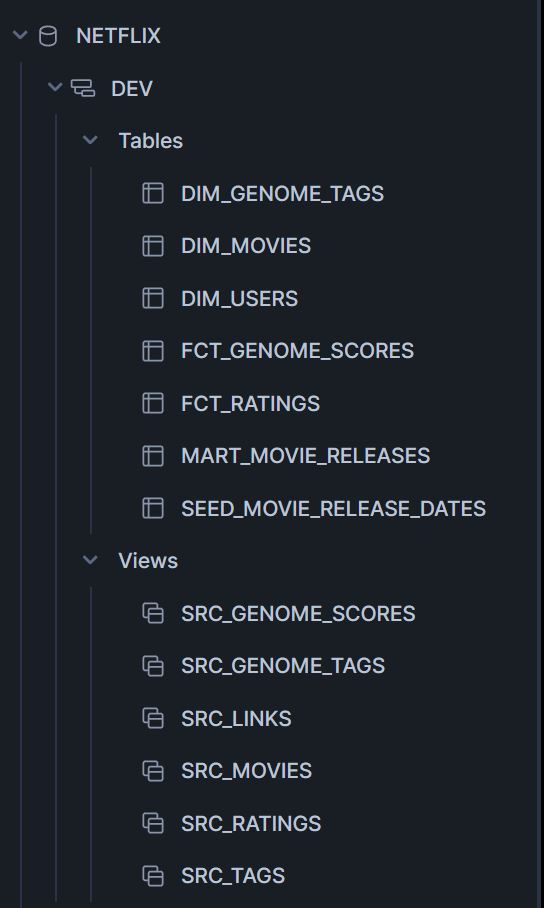
Tablas creadas en Snowflake separadas por ambiente dev y prod
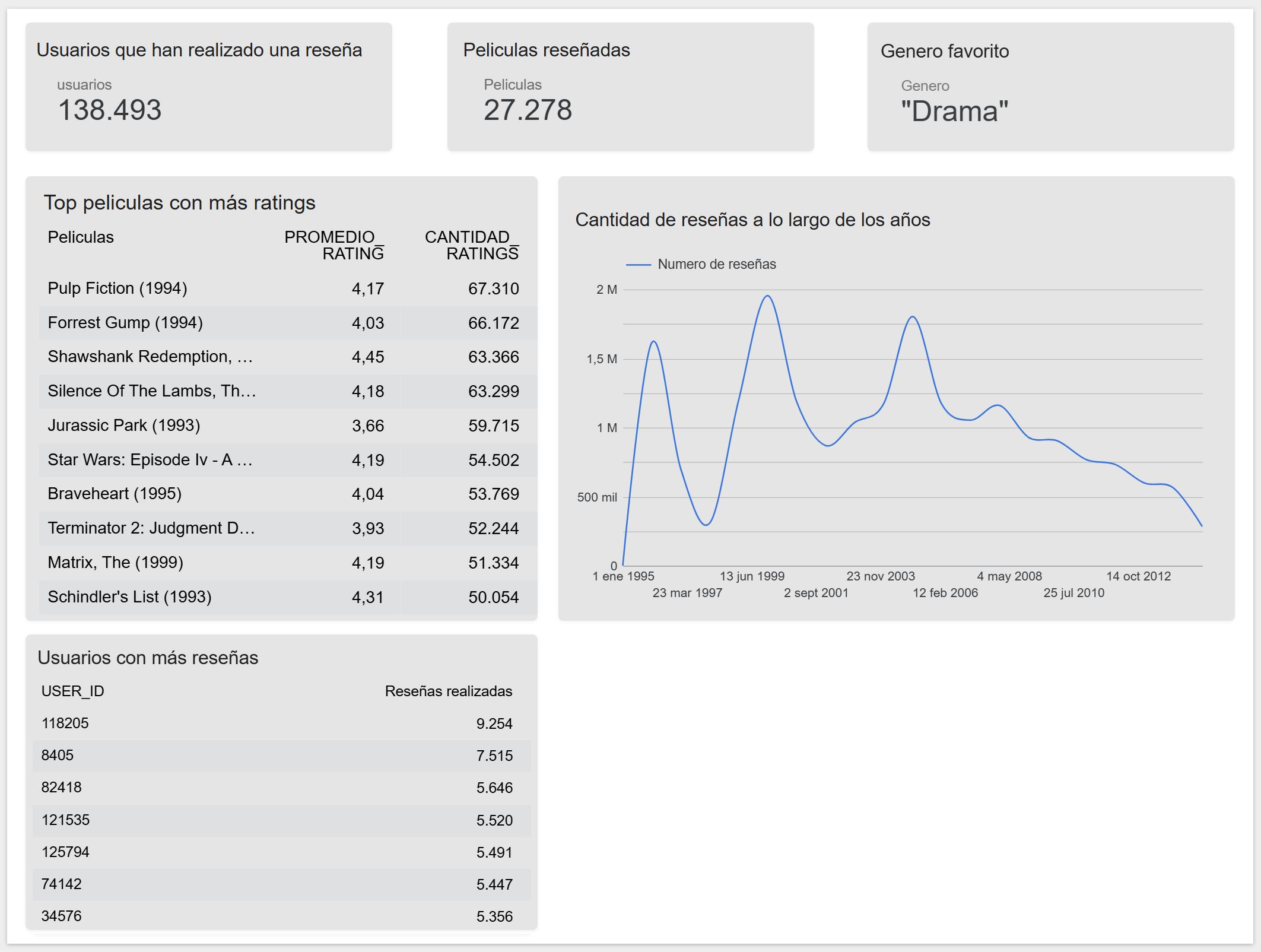
Dashboard
Dashboard resultante listo para consumir datos del prod
Código fuente
Accede al repositorio completo del proyecto en GitHub:
Este proyecto ETL fue desarrollado sin el uso de herramientas especializadas de orquestación como Apache Airflow, Luigi o Prefect, ni librerías ETL de alto nivel. El flujo de extracción, transformación y carga se implementó utilizando Snowflake y dbt, incluyendo pruebas de calidad de los datos para asegurar su consistencia e integridad. Cabe destacar que el dashboard incluido no está tan elaborado, ya que la finalidad principal del proyecto era procesar y preparar los datos para análisis, no crear visualizaciones avanzadas.